Ollamaとは?ローカルLLMが今注目される理由
「ChatGPTに入力した業務データが学習に使われていないか不安…」と感じたことはありませんか?クラウド型AIは手軽な反面、データの取り扱いに不透明な部分が残ります。そこで注目されているのが、自分のPC上でAIを動かすローカルLLM(Large Language Model)という選択肢です。
クラウドAIとローカルAIの決定的な違い
クラウドAI(ChatGPT・Geminiなど)はインターネット経由でリクエストを送り、外部サーバーで処理が行われます。一方、ローカルAIはすべての処理を自分のマシン上で完結させるため、入力データが外部に送信されることはありません。
クラウドAI vs ローカルAI 比較
| 項目 | クラウドAI | ローカルAI |
|---|---|---|
| 月額コスト | 2,000〜3,000円〜 | 完全無料 |
| オフライン利用 | 不可 | 可能 |
| データ送信 | 外部サーバーへ送信 | ローカル完結 |
| カスタマイズ性 | 制限あり | 自由度が高い |
Ollamaが選ばれる3つの理由(無料・オフライン・プライバシー)
Ollamaは、ローカルLLMを手軽に動かすためのオープンソースツールです。2023年のリリース以降、GitHubのスター数は9万を超え(2026年3月時点)、世界中の開発者・研究者に採用されています。
- 完全無料:本体も対応モデル(Llama 3・Gemma 3など)もすべて0円で利用可能
- オフライン動作:一度モデルをダウンロードすれば、ネット接続なしで使い続けられる
- プライバシー保護:医療・法律・社内情報など機密性の高い用途でも安心して活用できる
たとえば、月額2,500円のAPIコストを年換算すると約3万円。Ollamaに切り替えることで、このコストをまるごと削減できます。ランニングコストがかからない点は、個人・中小企業にとって大きなメリットといえます。
Ollama動作環境と推奨スペックの確認
「自分のPCでOllamaは動くのだろうか?」と不安に感じていませんか?実はOllamaは幅広い環境に対応しており、スペックさえ把握しておけばスムーズに導入できます。まず対応OSと最低限必要なハードウェア要件を確認しておきましょう。
OS別の対応状況(Windows・macOS・Linux)
Ollamaは2026年現在、主要な3つのOSに正式対応しています。それぞれ対応状況に若干の違いがあるため、自分の環境を事前にチェックしておくことが重要です。
- macOS:Apple Silicon(M1〜M4)およびIntel Mac両対応。Apple Siliconでは統合メモリをGPUとして活用できるため、特に相性が良いといえます。
- Windows:Windows 10以降に対応。NVIDIA GPU(CUDA対応)またはAMD GPU(ROCm対応)があれば高速推論が可能です。
- Linux:Ubuntu 20.04以降を推奨。NVIDIA・AMD・Intelの各GPUドライバーに対応し、サーバー運用にも適しています。
GPU・RAM・ストレージの最低ラインと快適動作ライン
モデルのサイズによって必要なリソースが大きく異なります。「最低ライン」と「快適動作ライン」を分けて把握しておくと、導入後のストレスを防げます。
【最低ライン(7Bモデル動作)】
- RAM:8GB(ただし他アプリを閉じた状態が前提)
- VRAM:4GB以上(GPU利用の場合)
- ストレージ:空き10GB以上(モデル1本あたり4〜5GB)
【快適動作ライン(13B〜34Bモデル対応)】
- RAM:16〜32GB
- VRAM:8〜16GB(NVIDIA RTX 3060以上を推奨)
- ストレージ:空き50GB以上(複数モデルを試す場合)
GPUがない環境でもCPUのみで動作しますが、7Bモデルで1トークンあたり3〜10秒程度かかる場合があります。快適に使いたい場合はGPUの用意をおすすめします。まずは自分のマシンスペックと照らし合わせて確認してみてください。
VRAM 12GBのコストパフォーマンスが高いGPUとして定評があるNVIDIA GeForce RTX 3060 12GBは、ローカルLLM入門の定番選択肢のひとつです。実際の価格や在庫状況はAmazonや価格.comでぜひ確認してみてください。
Ollamaのインストール手順(全OS対応)
「環境構築で詰まってAIツールを諦めた」という経験はありませんか?Ollamaはそのハードルを大幅に下げており、どのOSでも5〜10分以内に使い始められます。前セクションで確認した推奨スペック(RAM 8GB以上・空きストレージ10GB以上)を満たしていれば、あとは手順通りに進めるだけです。
Windowsへのインストールと動作確認
Windowsではインストーラーを実行するだけで完結します。コマンドライン操作は動作確認の1回のみです。
1
インストーラーをダウンロード
公式サイト(ollama.com)にアクセスし、「Download for Windows」ボタンからOllamaSetup.exe(約60MB)を取得します。
2
インストーラーを実行
ダウンロードしたOllamaSetup.exeをダブルクリックします。UACの確認画面で「はい」を選択すると、1〜2分でインストールが完了します。
3
動作確認
コマンドプロンプトまたはPowerShellを開き、ollama --versionを実行します。バージョン番号(例:ollama version 0.5.x)が表示されれば成功です。
4
モデルを試し実行
ollama run llama3.2を実行するとモデルのダウンロード(約2.0GB)が始まります。完了するとチャット入力モードになり、すぐに会話できます。
NVIDIAのGPUを搭載している場合、OllamaはCUDAドライバーを自動検出してGPU処理に切り替えます。タスクマネージャーの「GPU」使用率が上昇していれば、GPU加速が有効な証拠です。CPUのみと比較して応答速度が3〜10倍向上するケースもあります。
macOS・Linuxへのインストール方法
macOSはApple Silicon(M1〜M4)に最適化されており、統合メモリを最大限に活用します。LinuxはコマンドひとつでOK。どちらも所要時間は3分以内です。
1
【macOS】アプリをダウンロードして配置
公式サイトからOllama-darwin.zip(約50MB)をダウンロードし、解凍したアプリを「アプリケーション」フォルダへ移動します。アプリを起動するとメニューバーにアイコンが表示され、バックグラウンドでサーバーが起動します。
2
【Linux】コマンド1行でインストール
ターミナルを開き、以下を実行するだけです。スクリプトが自動的にアーキテクチャ(x86_64・ARM)を判定してインストールします。所要時間は30秒〜1分程度です。
curl -fsSL https://ollama.com/install.sh | sh3
動作確認(共通)
ターミナルでollama --versionを実行してバージョン番号を確認します。その後ollama run gemma3などを試すと、Apple SiliconではCPU処理と比べて2〜4倍の速度でレスポンスが返ってきます。
LinuxでNVIDIA GPUを使う場合の注意点:事前にnvidia-smiコマンドでドライバーの動作を確認してください。ドライバーが未インストールだとCPUのみの動作となり、7Bモデルでも応答に20〜60秒かかることがあります。

モデルのダウンロードと基本コマンドの使い方
インストールが完了したら、次はモデルを取得してチャットを試してみましょう。Ollamaはコマンド一つで主要なオープンソースLLMを手元に呼び出せるのが最大の強みです。
ollama pullでモデルを取得する方法
モデルのダウンロードは ollama pull コマンドで行います。取得したいモデル名を引数に指定するだけで、自動的に端末へ保存されます。
ターミナルを開く
macOS・LinuxはTerminal、WindowsはコマンドプロンプトまたはPowerShellを起動します。
pullコマンドを実行する
たとえばMetaの軽量モデル「Llama 3.2(3B)」を取得する場合は以下を入力します。
ollama pull llama3.2ファイルサイズはモデルによって異なり、3Bクラスで約2〜3GB、7Bクラスで約4〜5GBが目安です。回線速度によりますが、数分〜15分程度でダウンロードが完了します。
取得済みモデルを確認する
プログレスバーが100%になったら完了です。ollama list を実行すると保存済みモデルの一覧が表示されます。
主要モデルのpullコマンド早見表
ollama pull llama3.2:Meta製・3B、日常用途に最適ollama pull mistral:Mistral AI製・7B、バランス重視ollama pull gemma3:Google製・4B、コード生成に強いollama pull qwen2.5:Alibaba製・7B、日本語精度が高め
ターミナルでチャットを始める基本コマンド一覧
モデルの準備が整ったら、ollama run コマンドで対話セッションを開始できます。専用のUIは不要で、ターミナルに質問を打ち込むだけで回答が返ってきます。
ollama run llama3.2起動すると「>>>」プロンプトが表示され、自由に質問を入力できます。終了するには /bye と入力してEnterを押すだけです。
| コマンド | 操作内容 |
|---|---|
ollama pull <モデル名> |
モデルのダウンロード |
ollama run <モデル名> |
チャットセッションの開始 |
ollama list |
取得済みモデルの一覧表示 |
ollama rm <モデル名> |
モデルの削除 |
ollama serve |
APIサーバーの手動起動(ポート11434) |
日本語での回答精度はモデルによって大きく差が出ます。日本語を重視する場合は qwen2.5 や elyza シリーズをまず試してみてください。同じハードウェアでも、モデルの選択だけで体感品質が1.5〜2倍ほど変わるといわれています。
PythonでOllama APIを使ったチャットボットの自作方法
「ターミナルでのチャットはできたけど、自分のアプリに組み込みたい」と感じたことはありませんか?ollama公式のPythonライブラリを使えば、わずか数十行のコードでオリジナルのチャットボットが完成します。会話履歴の保持まで対応した実装例を、ステップごとに見ていきましょう。
ollama Pythonライブラリのインストールと初期設定
まず前提として、Python 3.8以上とOllamaのデーモンが起動している状態を確認してください。ライブラリ自体は公式PyPIに公開されており、インストールは1コマンドで完了します。
pipでライブラリをインストール
ターミナルで以下を実行します。バージョンは執筆時点で0.4系が最新です。
pip install ollamaインポートと疎通確認
Pythonインタープリタを起動し、モデル一覧が返ってくれば接続成功です。
import ollama
print(ollama.list())ポイント:Ollamaデーモンが起動していないと ConnectionRefusedError が発生します。ollama serve コマンドをあらかじめ実行しておくか、macOSならメニューバーのOllamaアイコンがアクティブであることを確認してください。
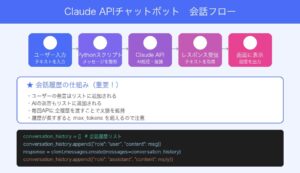
会話履歴を保持するチャットボットのコード例
単発の質問応答と異なり、実用的なチャットボットには「直前の会話を覚えている」機能が不可欠です。ollama.chat() はメッセージをリスト形式で受け取るため、履歴をそのまま蓄積して渡すだけで文脈を保持できます。
import ollama
MODEL = "llama3.2"
history = []
print("チャットボット起動中(終了は 'exit')")
while True:
user_input = input("あなた: ")
if user_input.lower() == "exit":
break
history.append({"role": "user", "content": user_input})
response = ollama.chat(model=MODEL, messages=history)
assistant_msg = response["message"]["content"]
history.append({"role": "assistant", "content": assistant_msg})
print(f"AI: {assistant_msg}\n")コードの構造はシンプルで、history リストにユーザーとAIの発言を交互に追加し、毎回 ollama.chat() に渡しているだけです。会話が長くなるとトークン数が増えてレスポンスが遅くなるため、実運用では直近10〜20ターン程度に切り詰める処理を追加するとよいでしょう。
このコードでできること
- 複数ターンにわたる文脈を維持した対話
- モデル名を変数で管理し、1行の変更で別モデルに切り替え可能
- ターミナル上での即時動作確認(追加ライブラリ不要)
まずはこのコードをそのまま動かし、MODEL の値を gemma3 や mistral に変えて各モデルの回答スタイルの違いを体感してみてください。
OpenWebUIでChatGPT風のブラウザUIを導入する方法
コマンドラインでのやり取りに少し慣れてきたころ、「もっと直感的に使いたい」と感じたことはありませんか?そこで役立つのがOpenWebUIです。ブラウザ上でChatGPTとほぼ同じ感覚でローカルLLMと会話できる、オープンソースのフロントエンドツールです。
Dockerさえ用意できれば、コマンド1行で起動できます。ローカル環境に閉じているため、入力した情報が外部に送信される心配もありません。
DockerでOpenWebUIを起動するステップ
Docker Desktop(バージョン24以上推奨)が導入済みであれば、以下の手順で5分以内に環境が整います。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:mainhttp://localhost:3000 を開き、管理者アカウントを作成します(初回のみ)。ollama pull 済みのモデルが自動で表示されていることを確認します。ポイント:--add-host=host.docker.internal:host-gateway オプションは、DockerコンテナがホストのOllamaサーバー(ポート11434)と通信するために必要です。これを省略すると接続エラーになるため注意してください。
複数モデルの切り替えと快適操作のコツ
OpenWebUIの強みの一つが、会話中にモデルをワンクリックで切り替えられる点です。たとえば、日本語の要約にはllama3.2、コード生成にはdeepseek-coder-v2と使い分けることで、応答精度が体感で1.5〜2倍向上するケースもあります。
- チャット画面上部のドロップダウンからモデルを即時切り替え可能
- 会話履歴はブラウザのローカルDBに保存され、セッションをまたいで参照できる
- 「システムプロンプト」をテンプレート化して保存しておくと、毎回の設定が不要になる
- ダークモード・日本語UI対応済みで、設定画面から変更できる
特にシステムプロンプトのテンプレート機能は、用途別に3〜5パターン用意しておくだけで作業効率が大きく変わります。まずは公式デモ動画や設定画面を確認してみてください。
2026年版おすすめローカルLLMモデル比較
「どのモデルを選べばいいのかわからない」と感じたことはありませんか?Ollamaで利用できるモデルは2026年現在で100種類を超えており、選択肢の多さに迷うのも無理はありません。用途とマシンスペックに合わせて選ぶことが、快適なローカルLLM体験への近道です。
用途別おすすめモデル一覧(日本語・コード生成・汎用)
用途が決まれば、モデル選びは一気に絞り込めます。以下の表を参考に、まず自分の「主な使い方」を確認してみてください。
| 用途 | おすすめモデル | サイズ目安 | 特徴 |
|---|---|---|---|
| 日本語対話 | Llama3-ELYZA-JP-8B | 約5GB | 日本語自然な応答、商用利用可 |
| コード生成 | Qwen2.5-Coder-7B | 約4.5GB | Python・JS・Rustに強く補完精度が高い |
| 汎用(軽量) | Gemma3-4B | 約3GB | 8GB RAMでも快適、英日どちらもこなせる |
| 汎用(高精度) | Mistral-Nemo-12B | 約8GB | 推論・要約・翻訳のバランスが秀逸 |
日本語精度を重視するなら、ELYZAシリーズが現時点でもっとも実用的な選択肢のひとつです。ChatGPT-3.5に近い自然さで会話できるという報告も多く見られます。
モデルサイズと応答速度・精度のバランスの選び方
モデルサイズが大きいほど精度は上がる一方、応答速度とRAM使用量がネックになります。一般的な目安として、7〜8Bクラスのモデルは16GB RAM環境でトークン生成速度が毎秒20〜40トークン程度出ることが多く、日常使いには十分な速さといえます。
RAMを確認する
8GB → 3〜4Bモデル、16GB → 7〜8Bモデル、32GB以上 → 13B以上も快適に動作します。
GPUの有無を確認する
M1/M2/M3 Macや、NVIDIA GPU(VRAM 8GB以上)があれば、CPU推論より3〜5倍高速に動作します。
用途に合わせてモデルを選ぶ
まず上記の用途別一覧で候補を絞り、ollama pull モデル名 で試験導入するのがおすすめです。
量子化(Quantization)されたモデルを選ぶと、精度をほぼ維持しながらファイルサイズを30〜50%削減できます。たとえば13BモデルのQ4版は、元サイズの約半分である8GB前後で動作するため、RAMに余裕がない場合の有力な選択肢です。ぜひ自分の環境に合ったモデルを試してみてください。
よくあるエラーとトラブルシューティング
おすすめモデルを選んで実際に動かしてみたものの、「画面が固まってしまった」「APIに全然つながらない」という経験はありませんか。初回セットアップ時は誰でも一度はつまずくポイントです。原因のほとんどはパターンが決まっているので、落ち着いて順番に確認していきましょう。
モデルが重くて動かない場合の対処法
最も多い原因は、搭載RAMに対してモデルが大きすぎることです。たとえば8GBのメモリ環境でllama3:70bを起動しようとすると、スワップ(仮想メモリ)が大量に発生し、応答に数十分かかることがあります。まず自分の環境に合ったモデルサイズを選び直すことが先決です。
目安:RAM別の推奨モデルサイズ
8GB RAM → 7Bモデルまで(例:llama3.2:3b、gemma3:4b)
16GB RAM → 13Bモデルまで(例:phi4:14b)
32GB以上 → 30B〜70Bモデルが現実的
ollama ps で実行中のモデルを確認し、不要なものを ollama stop モデル名 で停止するそれでも改善しない場合は、ModelfileでPARAMETER num_gpu 0と設定してGPUオフロードを無効化すると、CPU処理に切り替わり安定することがあります。速度は落ちますが、クラッシュよりは実用的です。
APIが応答しない・接続エラーの解決方法
Open WebUIや自作アプリからOllamaのAPIを叩いた際に「Connection refused」や「504 Gateway Timeout」が出るケースも頻出します。実はこの9割は、Ollamaのサーバーが起動していないか、ポートが競合しているだけです。
まず以下を順番に確認してください
- ターミナルで
ollama serveを実行してサーバーが起動しているか確認 - ブラウザで
http://localhost:11434にアクセスし「Ollama is running」と表示されるか確認 - ポート11434が他のプロセスに占有されていないか確認(
lsof -i :11434)
リモートからAPIを叩く場合は、環境変数 OLLAMA_HOST=0.0.0.0 を設定する必要があります。デフォルトではローカルホストからの接続のみ許可しているため、同一LAN内の別端末からアクセスするときも必ずこの設定を追加してください。
ファイアウォールにも注意
macOSのファイアウォールやWindowsのDefenderが11434番ポートをブロックしているケースがあります。セキュリティ設定でOllamaを「許可されたアプリ」に追加するか、一時的にファイアウォールを無効にして動作確認してみてください。
まとめ|Ollamaで自分だけのプライベートAI環境を手に入れよう
ここまで、Ollamaのインストールからモデルの導入、APIサーバーの起動、そしてトラブルシューティングまでを一通り解説してきました。クラウドサービスに月額数千円を払わなくても、自分のPCでLLMを動かせる時代はすでに到来しています。プライバシーを守りながら、インターネット環境がなくても使えるローカルAIは、ビジネス用途から個人の学習まで幅広く活躍します。
この記事でおさえたポイント
- Ollamaは無料・オープンソースでローカルLLMを手軽に動かせるツール
- Llama 3・Mistral・Gemmaなど主要モデルをコマンド1行で導入可能
- REST APIでOpen WebUIや外部アプリとの連携も簡単に実現
- 動作が重い・APIが応答しないエラーの多くはメモリ不足かポート競合が原因
セットアップ完了後に試したい活用アイデア5選
環境が整ったら、次は実際に使いこなすフェーズです。ローカルLLMならではの強みを活かした活用例を5つ紹介します。
社内ドキュメントの要約・検索(RAG構築)
LangChainやLlamaIndexと組み合わせてRAG(検索拡張生成)を構築すると、社外秘の資料をクラウドに送らずAIで検索・要約できます。
コードレビューの自動補助
VS CodeのContinueプラグインとOllamaを接続すれば、Copilot不要のオフラインAIコーディング補助が月額0円で実現します。
日記・メモの自動整理
ObsidianのLocalGPTプラグインと連携すると、ローカルのMarkdownノートをAIがタグ付け・要約してくれます。
翻訳・ライティング補助
Mistral 7BやGemma 3はマルチリンガル対応で、英語技術文書の和訳品質はDeepLに匹敵するレベルといわれています。
チャットボットのプロトタイプ開発
Open WebUIのカスタムプロンプト機能でキャラクターやペルソナを設定し、デモ用チャットボットを数分で作成できます。
快適なローカルLLM環境に必要なハードウェアまとめ
「動かせる」と「快適に使える」は別物です。モデルのサイズによって必要なスペックは大きく変わります。予算や用途に合わせて、下の目安を参考にしてください。
| 用途・モデル規模 | RAM目安 | GPU VRAM目安 | 推奨ハード例 |
|---|---|---|---|
| 軽量モデル(〜7B) | 16GB | 6〜8GB | RTX 3060 / M2 MacBook Air |
| 中規模モデル(13〜14B) | 32GB | 12〜16GB | RTX 4070 / M3 Pro MacBook Pro |
| 大規模モデル(32B〜) | 64GB以上 | 24GB以上 | RTX 4090 / M3 Max / Mac Studio |
Apple SiliconのMacはユニファイドメモリ方式のため、GPUとCPUがメモリを共有します。M3 Pro(36GB)であれば14Bモデルを1トークン/秒以上のレスポンスで動かせるという報告もあります。一方、WindowsのNVIDIA環境ではVRAMが最重要で、VRAM不足はそのまま生成速度の低下に直結します。
💡 ストレージも忘れずに
モデルファイルは7Bで約4〜5GB、70Bになると40GB超になります。モデルを複数導入する場合は、NVMe SSDで500GB〜1TB以上を確保しておくと安心です。HDDでは読み込みに数分かかることもあります。
ローカルLLMの世界は2025〜2026年にかけて急速に進化しており、6ヶ月前には70Bモデルが必要だった精度を、今では14Bモデルで達成できるケースも増えています。まずは手元のマシンで試してみて、用途に合わせてハードウェアを拡張していくアプローチがおすすめです。ぜひ自分だけのプライベートAI環境を構築して、AIの活用幅を広げてみてください。
VRAM 16GBを確保できるRTX 4060 Ti 16GBは、ローカルLLM用途では特にコストパフォーマンスに優れた選択肢のひとつです。気になる方は現在の価格や在庫状況をぜひ確認してみてください。
VRAMが12GBあれば7Bクラスのモデルを快適に動かせるため、これからローカルLLMを始める方にとって費用対効果の高い選択肢のひとつです。現在の価格や在庫状況はぜひ確認してみてください。
メモリ容量が不足すると、モデルのロード中にエラーが出たり、推論速度が極端に落ちたりすることがあります。32GBへの増設を検討している場合は、Crucial DDR5をぜひ確認してみてください。
Crucial製の64GB DDR5メモリ(2枚組)はOllamaでの大規模モデル運用に十分な容量を確保できるため、本格的にローカルLLMへ取り組みたい場合はぜひ確認してみてください。
ローカルLLMのモデルデータは数GB〜数十GBになることも多いため、読み書き速度と容量の両立が重要です。Samsung 990 Pro NVMe SSD 2TBは高速転送と大容量を兼ね備えた選択肢のひとつなので、ぜひ確認してみてください。
モデルのデータを高速に読み書きするSSDの性能は、推論速度に直結します。大容量かつ高速なWD Black SN850X NVMe SSD 2TBは、ローカルLLM環境の構築を検討している場合にぜひ確認してみてください。
Radeon 780Mを搭載したMINISFORUM UM780 XTXは、iGPUながらVRAMを最大16GB割り当て可能で、7Bクラスのモデルであれば十分な速度で動作するといわれています。ローカルLLM用のミニPCを検討している場合は、ぜひスペックを確認してみてください。
Core Ultra搭載で処理能力と省スペースを両立したMINISFORUM MS-01は、ローカルLLMの実行環境として人気の高い一台です。気になる方はぜひスペックや価格をチェックしてみてください。
Raspberry Pi 5 8GBは軽量モデルをローカルで動かす入門機として人気が高く、価格や在庫の最新情報はぜひ確認してみてください。
外出先でもローカルLLMを動かしたい場合は、大容量バッテリーと強力なAPUを搭載したASUS ROG Ally Xがひとつの選択肢となります。ぜひ公式スペックや実機レビューを確認してみてください。